
Pseudonymization Under GDPR: What Is Enough for Compliance?
When selecting the right technical measures to protect your data, pseudonymization is often a preferred option. This process is not only recommended by the GDPR but, in some cases, even required to be deemed compliant.
Recently, the European Data Protection Board (EDPB) published guidelines on pseudonymization to provide a clearer definition of the process, outline key requirements, and clarify when pseudonymization is sufficient for compliance.
As always, the effectiveness of pseudonymization depends on your specific situation and the purpose of using this safeguard. To better understand its requirements, let’s take a closer look at how pseudonymization works and explore some practical examples provided by the EDPB.
When Is Data Considered Pseudonymized?
While pseudonymization is a valuable tool for protecting personal data within your company, it should be approached with caution. Simply replacing identifiers does not automatically guarantee that data is secure. Proper pseudonymization requires a structured approach, including a well-executed pseudonymization transformation.
What Is a Pseudonymization Transformation?
A pseudonymization transformation is a process that replaces certain elements of original data with pseudonyms – new identifiers that can only be linked back to the data subject using additional information.
Key components of pseudonymization:
- additional information – any data that can be used to re-identify a person from pseudonymised data;
- direct identifiers – personal identifiers, such as national ID numbers, that are removed during the pseudonymization process;
- pseudonyms – new identifiers that replace direct identifiers and can only be linked back to individuals using additional information;
- secret data (‘Pseudonymization Secrets’) – this includes cryptographic keys (used for encryption or hashing) or lookup tables that map pseudonyms to the original data.
Important Considerations
Pseudonymization is not a one-size-fits-all solution, and there are crucial factors to consider when determining whether your data is truly pseudonymized and how it should be classified under GDPR.
- One key question to ask is: Can the data be attributed to a specific individual without access to additional information?
If the answer is yes, then the data may not be fully pseudonymized, and additional safeguards may be necessary.
- Another common question is: Can pseudonymized data still be considered personal data under the GDPR?
Under the GDPR, pseudonymized data remains personal data as long as it can be linked back to an individual using additional information. This means that even if direct identifiers have been replaced, the data is still subject to GDPR regulations if re-identification is possible.
Moreover, the additional information used for re-identification may itself be considered personal data and must also be handled in compliance with the GDPR.
- And the last popular misconception: Can pseudonymized data be classified as anonymous?
As GDPR puts it, pseudonymized data is still personal data, while anonymized data is not. For pseudonymized data to be classified as truly anonymous, all conditions for anonymity must be met. This means that even if the organization performing the pseudonymization erases its additional identifying information, the data will only be anonymous if no party, now or in the future, can reasonably re-identify individuals using any available means.
In short, pseudonymized data is not the same as anonymous data. While pseudonymization enhances privacy and security, it does not remove the data from the scope of GDPR, unlike proper anonymization.
Why Pseudonymization?
Pseudonymization is a valuable safeguard that offers numerous benefits under GDPR, aligning with key principles and legal provisions.
First of all, it helps ensure compliance with essential data protection principles such as lawfulness, fairness, accuracy, data minimization, confidentiality, and purpose limitation.
Secondly, by integrating pseudonymization, organizations can also uphold data protection by design and default, reinforcing privacy at every stage of data processing.
Beyond compliance, pseudonymization:
- enables the secure processing of data for research and statistical purposes, ensuring that sensitive information remains protected while still being useful for analysis;
- enhances the security of processing, reducing risks associated with unauthorized access or data breaches;
- supports processing based on the legitimate interests of the controller, as permitted under GDPR, while also helping to establish the compatibility of further processing with its original purpose.
Finally, pseudonymization plays a crucial role in data transfers, both when exporting data to third countries and when sharing pseudonymized information with third parties. By minimizing risks while maintaining data utility, pseudonymization is a key tool for organizations seeking to balance privacy, security, and compliance in today’s data-driven world.
EDPB Examples of the Application of Pseudonymization
Now, let’s take a closer look at the examples of the application of pseudonymization as outlined by the EDPB in their recent guidelines. These examples help illustrate how pseudonymization can be effectively implemented to enhance data protection while ensuring compliance with GDPR requirements.
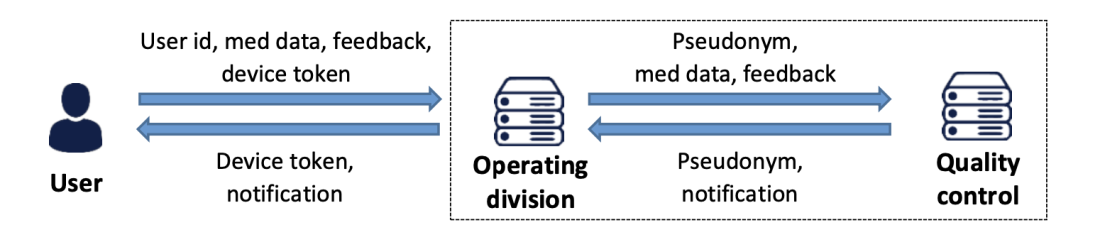
Case 1 – Data minimisation and confidentiality in internal analysis
Source of illustration: EDPB Guidelines on Pseudonymisation, adopted on 16 January 2025. Available at:https://www.edpb.europa.eu/system/files/2025-01/edpb_guidelines_202501_pseudonymisation_en.pdf
A company operates a medical advice app that analyzes user-submitted symptoms. To ensure quality control, a dedicated division evaluates whether the app’s recommendations align with established medical knowledge. In critical cases, users must be notified if incorrect advice has been given. However, to comply with data minimization (Article 5(1)(c) GDPR) and data protection by default (Article 25(2) GDPR), access to identifiable user data must be restricted.
To achieve this, the quality control division works with pseudonymized data – they analyze the information without access to user identities. If a notification is required, they pass only the pseudonym and message to the operational team, which holds the necessary additional data to re-identify users and send alerts securely. This approach minimizes confidentiality risks (Article 5(1)(f) GDPR) while preserving the ability to notify users when necessary.
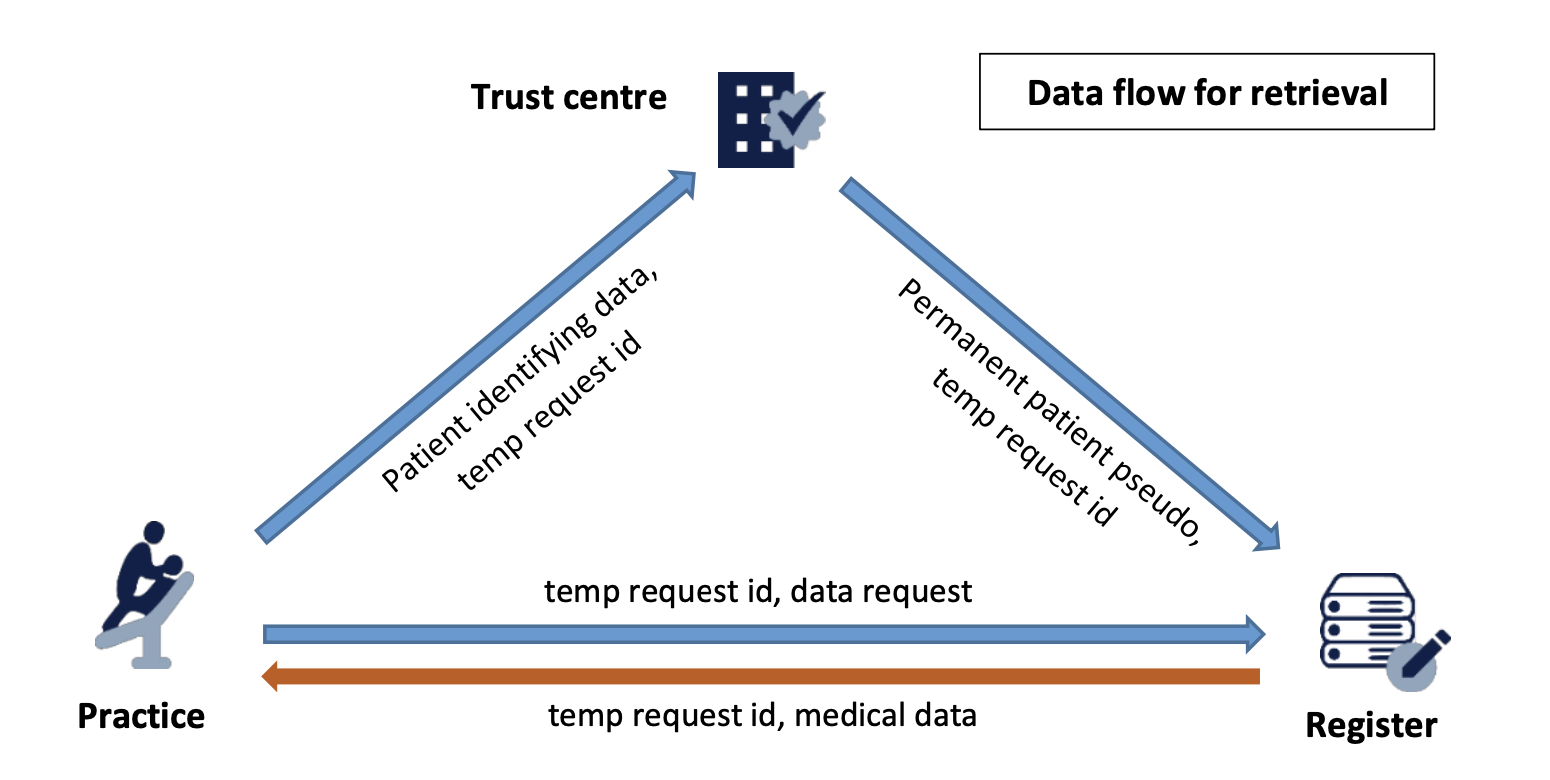
Case 2 – Data minimisation and purpose limitation in the course of external analysis
Source of illustrations: EDPB Guidelines on Pseudonymisation, adopted on 16 January 2025. Available at:https://www.edpb.europa.eu/system/files/2025-01/edpb_guidelines_202501_pseudonymisation_en.pdf
A national register collects data on dental implants to monitor quality and provide feedback to manufacturers and dental practices. Additionally, stored data can be accessed by future caregivers with patient consent. However, to comply with data minimization (Article 5(1)(c) GDPR) and data protection by default (Article 25(2) GDPR) while preventing unauthorized use (e.g., advertising), access to identifiable patient data must be strictly controlled.
To achieve this, pseudonymization is applied:
- The register can link cases related to the same patient or practice without revealing patient identities.
- Practices receive only aggregated quality reports.
- Subsequent caregivers can access relevant data using a controlled procedure.
- Implant quality is analyzed using anonymized findings.
Additional Safeguards:
- Original data remains confidential under professional secrecy obligations.
- A Trust Centre manages the lookup table linking patient identities to pseudonyms.
- All involved entities must follow strict data exchange protocols.
This setup ensures compliance while maintaining the necessary link between patients and their medical records in a secure and controlled way.
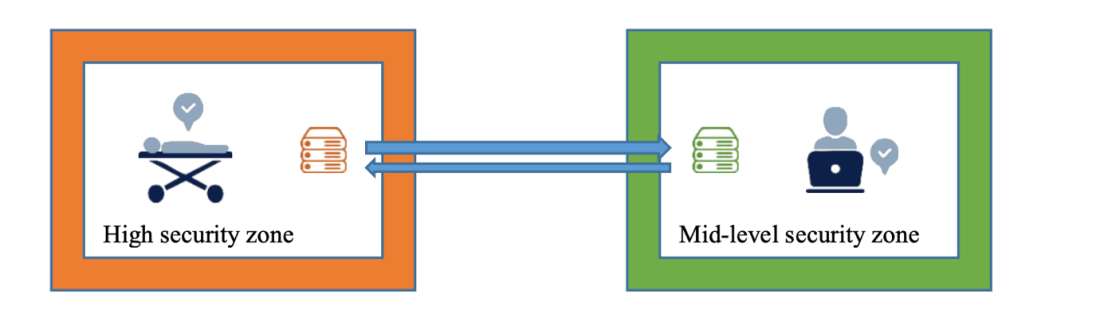
Case 3 – Reduction of confidentiality risks
Source of illustration: EDPB Guidelines on Pseudonymisation, adopted on 16 January 2025. Available at:https://www.edpb.europa.eu/system/files/2025-01/edpb_guidelines_202501_pseudonymisation_en.pdf
A large university hospital wants to optimize its service portfolio and billing procedures by analyzing treatment data. To ensure security, the hospital uses pseudonymised data stored in a dedicated database, which non-medical administrative staff access in a mid-level security environment. These staff members do not have access to the hospital’s main information system, making it impossible for unauthorized personnel to identify individual patients’ health statuses. The setup allows feedback to be provided to care managers if irregularities are found in the data, while maintaining privacy and security.
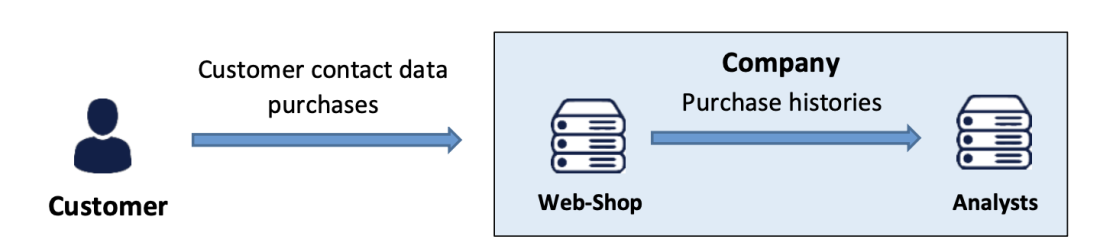
Case 4 – Risk reduction justifying further processing
Source of illustration: EDPB Guidelines on Pseudonymisation, adopted on 16 January 2025. Available at:https://www.edpb.europa.eu/system/files/2025-01/edpb_guidelines_202501_pseudonymisation_en.pdf
A company running a large web-shop wants to analyze customer purchase data to find correlations between products. However, purchase records could reveal sensitive information about customers, such as their economic situation or personal preferences, which could lead to profiling under GDPR. To avoid this, the company pseudonymises the data, ensuring that analysts cannot link the data to specific individuals. The analysis results are aggregated, and all personal data is erased afterwards. This processing minimizes impact on customers and allows the company to assess whether the analysis purpose is compatible with the original data collection purpose, in line with GDPR requirements.
Case 5 – Separation of functions allowing for data minimisation, purpose limitation, and confidentiality
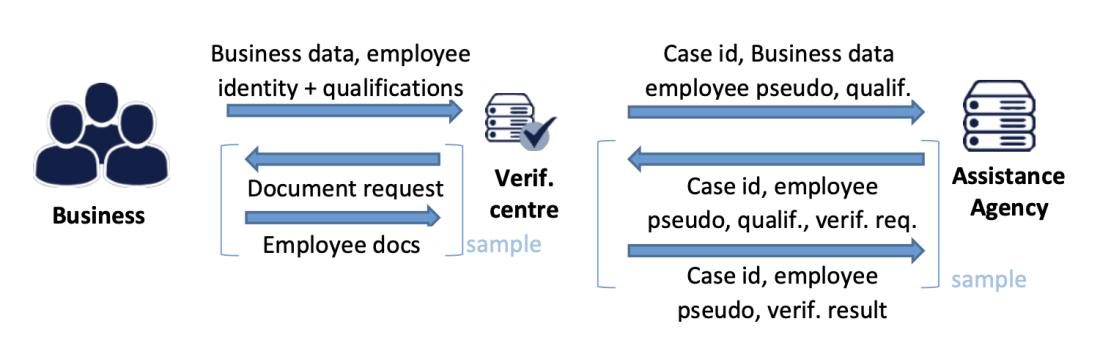
Source of illustration: EDPB Guidelines on Pseudonymisation, adopted on 16 January 2025. Available at:https://www.edpb.europa.eu/system/files/2025-01/edpb_guidelines_202501_pseudonymisation_en.pdf
An agency responsible for paying subsidies to businesses verifies applications based on criteria related to the business and its employees. To minimize access to employee data and comply with GDPR’s data minimisation principle, the agency only provides a pseudonym and qualification data of employees to a Verification Centre in randomly selected cases or when there is suspicion of fraud. The Verification Centre uses a lookup table to match the pseudonym to the employee’s identity and requests additional documents from the business to verify the employee’s identity and qualifications. This approach reduces the risk of unnecessary data exposure and ensures the data is used only for the intended purpose.
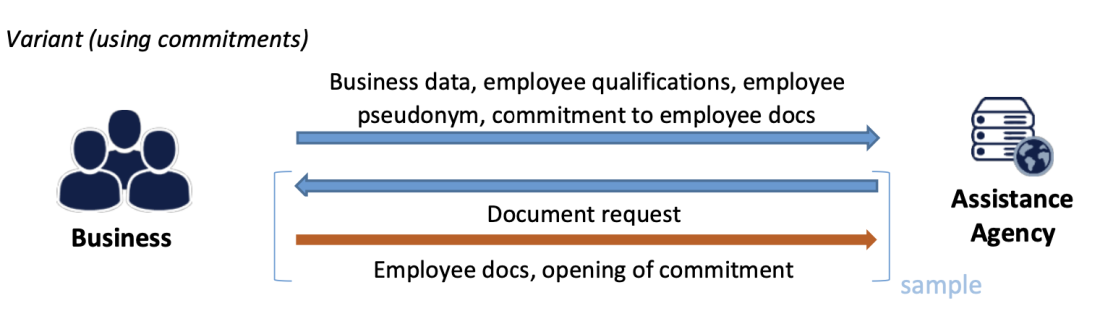
Source of illustration: EDPB Guidelines on Pseudonymisation, adopted on 16 January 2025. Available at:https://www.edpb.europa.eu/system/files/2025-01/edpb_guidelines_202501_pseudonymisation_en.pdf
To avoid the need for an additional Verification Centre, the Agency can use cryptographic methods. A web app is provided to businesses, allowing them to pseudonymise employee data themselves. The pseudonyms include cryptographic commitments to the employee documentation.
In randomly selected cases or where there are concerns, the Agency (or a dedicated unit) requests the original documents from the business to verify the identity and qualifications of specific employees. The cryptographic commitment ensures that the Agency controls which documents are requested, preventing businesses from substituting data for different employees.
GDPR Fines for the Lack of Correctly Implemented Pseudonymization
The failure to correctly implement pseudonymization continues to be one of the major compliance risks under the GDPR. Several recent fines imposed by European Data Protection Authorities (DPAs) highlight the consequences of improper data handling, particularly when organizations misrepresent anonymization, fail to implement necessary security measures, or neglect to pseudonymize sensitive data.
Avast Software (Czech Republic) – €13.9 million fine
One of the most significant fines for misleading pseudonymization was imposed by the Czech DPA on Avast Software s.r.o. The company improperly transferred pseudonymized Internet browsing data of around 100 million antivirus users to the US-based company Jumpshot, falsely claiming that the data was anonymized. However, the transfer included unique user IDs, allowing partial re-identification of individuals. Avast failed to provide users with accurate information regarding the nature of the data being shared, violating GDPR principles of transparency and data protection by design.
Fortum & PIKA (Poland) – €1 million & €53,000 fines
The Polish DPA issued fines to both Fortum Marketing and Sales Polska S.A. (€1 million) and its data processor, PIKA Sp. z o.o. (€53,000) for failing to protect customer data during an IT infrastructure change. PIKA, responsible for handling customer data, did not pseudonymize or encrypt the data, making it vulnerable to unauthorized access.
The breach occurred when an additional customer database was created on an unsecured server, allowing unauthorized third parties to access and extract customer data. Additionally, PIKA had used real customer data instead of test data during system testing, further exposing sensitive information. Fortum, as the data controller, was fined for failing to monitor its processor’s security measures, violating GDPR’s accountability and risk management obligations.
EU DisinfoLab & Researcher (Belgium) – €2,700 & €1,200 fines
The Belgian DPA fined EU DisinfoLab (€2,700) and a researcher (€1,200) for failing to pseudonymize personal data in a 2018 political research project. The organization processed data from 55,000 Twitter accounts, including 3,300 political profiles, as part of an analysis on the ‘Benalla affair’ in France. However, the raw dataset was published without pseudonymization or other security measures, exposing individuals to potential discrimination and reputational harm. The dataset contained highly sensitive information, such as political views, religious beliefs, ethnic origin, and sexual orientation. The DPA ruled that the publication violated GDPR principles on lawfulness, transparency, and data security.
Conclusion
As the data controller, it is your responsibility to determine the most appropriate measures to ensure GDPR compliance. When selecting pseudonymization as a safeguard, it is crucial to approach it with caution and thoroughness, taking into account the specific aspects of this technique.
A risk-based approach should be adopted when implementing pseudonymization, considering the nature and potential risks of the processing. Regular reviews of practices are essential to stay aligned with evolving technologies and emerging threats.
Important: Keep in mind that pseudonymization, by itself, is generally insufficient to guarantee full compliance with data protection regulations. It should be integrated into a broader set of technical and organizational measures to ensure comprehensive data protection.
In case of doubt, you should consult your data protection officer or legal team; here at Legal IT Group, our experienced data protection officers may also guide you through privacy engineering processes and help you strengthen the GDPR compliance program.