
Technical aspects of GDPR compliance
The GDPR establishes the fundamental principles of personal data processing, but, at the same time, the regulation does not provide preferable technologies or methods. Thus, to bring the system into compliance with the regulation, it is necessary to obtain that information from third-party sources. The logic of the regulation creators is that the variability of scenarios, the uniqueness of each case, and the dynamics of the industry do not allow the creation of clear and long-lasting guidelines. So, the technical aspects of GDPR are aimed to continuously provide practical instructions and recommendations, reflecting best practices of cybersecurity.
In the process of bringing the system into compliance with GDPR, several overlapping approaches have a positive effect on the level of information security.
The information security model defines the vectors of system construction, flexibility, and scalability.
The data life cycle is a visualization of data flow, that helps to analyze weaknesses of the system, potential vulnerabilities, and countermeasures to them.
Risk control is a process that determines potential negative events, probability of occurrence, and negative consequences. In addition, risk control is crucial in the development of high-quality and detailed algorithms for countering threats.
Information security model
According to manufacturers, it seems, that it is enough to use expensive and high-quality equipment with the latest software to provide decent information security. However, that is only partially true. On the one hand, using modern hardware and software simplifies some processes and provides a wider toolkit with up-to-date security protocols. On the other hand, the biggest weakness of any system is the human factor. When it is impossible to get information via technology, there is a much higher chance to get access via human interaction.

Therefore, it is possible to claim that information security is not a result, but a process. The state of security fluctuates due to dynamic external and internal factors. Maintaining the proper state of information security requires constant efforts and numerous measures throughout the system’s existence.
For example, we are talking about:
- System monitoring
- Risk assessment
- Compliance with the current needs of the company
- Implementation of modern practices and standards
- Active and rapid response to potential and active threats.
- Improvement of staff qualifications
The model of information security acts as a foundation upon which methods, algorithms, and policies of information security are built. Information security models are usually can be adapted to multiple use cases. The structure can be borrowed from other institutes, including corporate and even military. The ultimate goal is to reduce the risk of negative consequences, minimize potential harm, and create safe templates and action algorithms.
Based on structure, you can separate the following simplified variations:
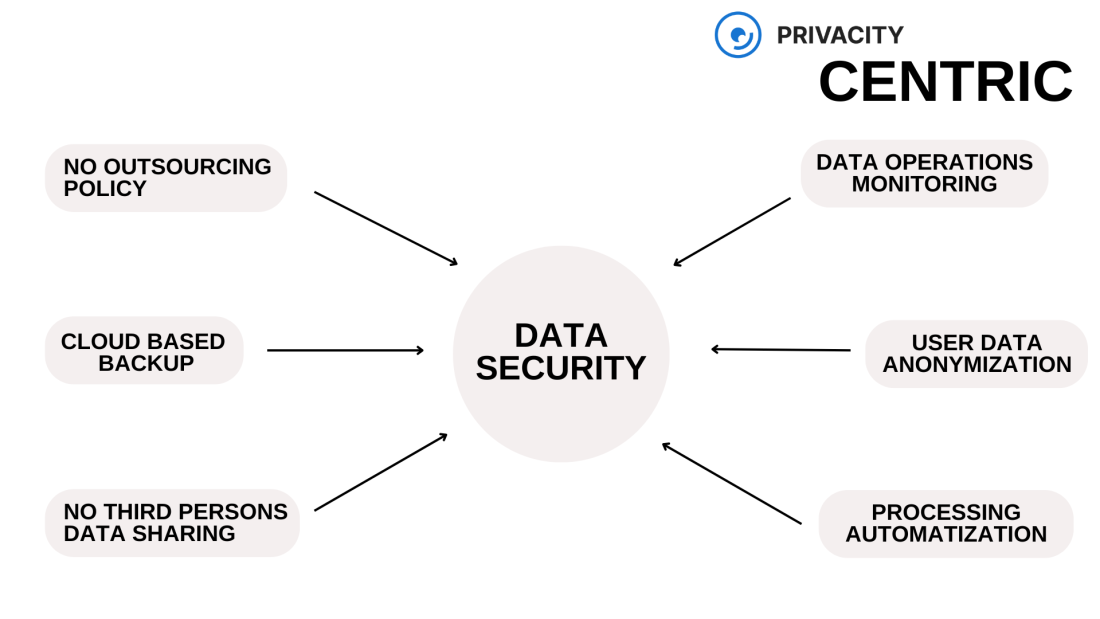
→ “centric” – risk reduction occurs due to the simultaneous implementation of independent protection mechanisms aimed at achieving the same goal.
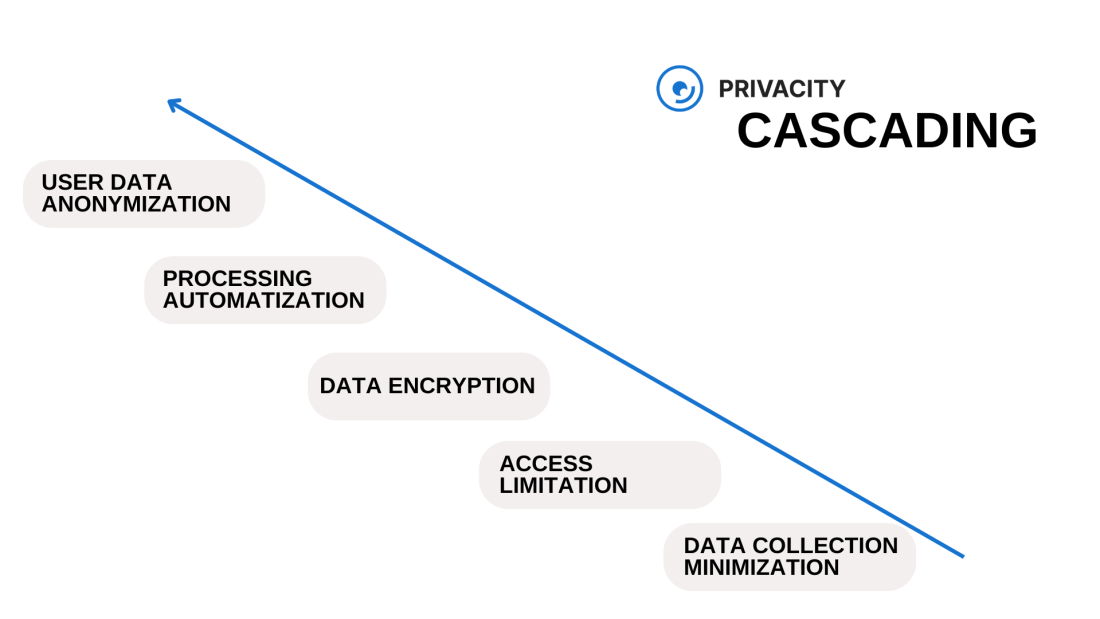
→ “cascading” – risk reduction occurs due to multi-stage protection, where each subsequent step compensates for the ineffectiveness of the previous one.
→ “pyramidal” – the risk is reduced by creating a clear hierarchy of means of protection and combining them to achieve a better result. Also, this model is precepted as something in between “centric” and “cascading” models.
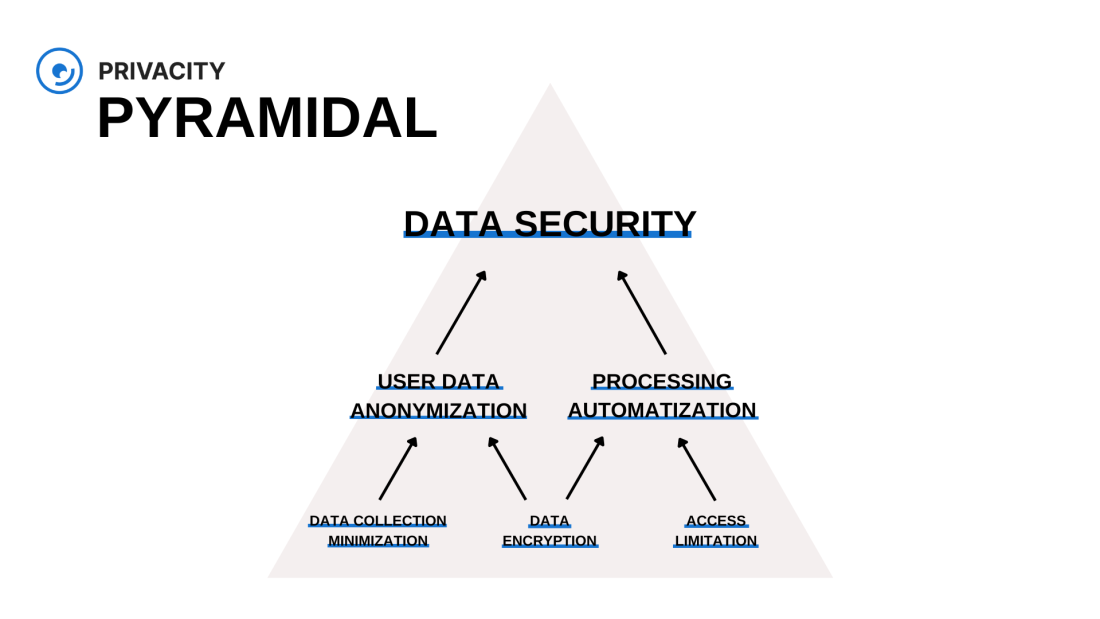
It’s quite hard to find an actual system that uses only one model for all its aspects. But in this way, it is easier to build the core logic of a system. As an example, let’s use a cascade model, that is often referred to as a “defense onion”. This design is simple and universal. Each subsequent layer tries to eliminate the failure of the previous ones, protecting its core. The logic of this model is based on prohibitions to perform certain actions to reduce risks and actions when damage is inevitable.
→ Do not collect – an external “layer” that allows you to automatically cut off unnecessary information. The absence of data in the system makes it impossible to be lost or leaked. For example, modern smartphones can collect a huge amount of information from various sources. For example, a navigation application only needs the geolocation of the user, but not the full range of data that the device can provide. Accordingly, the collection and transfer of information should be limited to key information only.
→ Do not save – involves saving only necessary information. The less data there is in the system, the lower the probability that it will be affected by a negative event. That is, if there are no grounds for storage, the information must be deleted immediately. This rule applies to all confidential information in the system.
→ Do not grant access – involves access rights to stored information. The fewer employees, outsourced specialists, users, and third parties will have access to key information, the lower the probability of insider attacks or information leakage. In addition to the fact of access itself, the volume of data to which access is granted also must be regulated.
→ Prevent negative events – covers control and active countermeasures against both external and internal threats. The probability of negative events never equals zero, as there are always external and internal factors that are difficult to predict. For example, software error, hardware failure, human error, or large-scale nature or human-made disasters. Risk control allows you to determine the most likely negative events and take measures to prevent them.
→ Do not allow negative consequences – provides for countermeasures against negative events. Having appropriate algorithms and policies can reduce consequences to almost zero. For example, data backup provides an opportunity to completely restore lost due to server malfunction information.
→ Mitigate negative consequences – provides action algorithms in case it is impossible to avoid negative consequences completely. Under such conditions, it is necessary to minimize the impact of negative events on key and important information. Firstly, the protection of confidential and key data must be prioritized, as secondary corporate and non-essential information should be saved. Algorithms should include not only internal measures and notifications but also interaction with specialized control bodies.
Data life cycle
The life cycle of data can have different meanings based on scale. In a broader sense, we are talking about the general information existence, starting from the moment of creation and until its destruction. In a narrower sense, it refers to the information within a specific system. Such a cycle starts with information collection and ends with its deletion from a system. In the context of information security and GDPR compliance, we will look closer into the second option.
At the initial development stages of companies’ data life cycles, usually, there is no consistent structure of data flow. Thus, its visualization would be very useful to demonstrate the internal processes and for further systematization of the chaotic flow of information. Each type of data has its life cycle within a company and its structure depends on:
- type of information
- the primary purpose of the collection
- sources
- third parties’ participation
- features of the company and its products.
For example, the cycle of payment information is significantly different from account identifiers or third parties marketing analytics.
→ Collecting – starts the life cycle of information. This stage is predetermined by porpoise and conditions of collection. For example, the amount of collected information as well as collection mechanisms are chosen based on company needs and then mirrored in users’ data collection agreement. For example, the user of the web application must give his consent to the processing of his data. Users must be informed about the collection of that data, the purposes of collection, and the mechanisms of its processing. The information processor, on the other hand, cannot change the terms without the user’s consent.
→ Processing – is the stage of the cycle in which calculations and data manipulations take place. This step may contain several processes and data manipulations aimed at achieving the goal of that data collection.
→ Retention – is the stage of intermediate data storage. Statistically, the largest number of negative events occurs during the storage of information. Thus, the utmost attention must be paid to integrity, accuracy, and confidentiality. In the practical aspect, we are talking about the implementation of reservation, encryption, pseudo-anonymization, access restriction policies, and other mechanisms of information security.
→ Information disclosure – is about information transfer outside the system. Unlike other parts of the lifecycle, disclosure is optional. Such data transfer must guarantee the preservation of confidentiality, both during the transfer itself and by a third party, that will receive it. In practice, this stage is often used to transfer marketing and statistical information. For that use case, data must be anonymized before its disclosure and transferred through safe protocols.
→ Destruction – is the end of the data life cycle. According to the GDPR, confidential information must be stored based on the legal basis or the consent of the owner of the information. In other cases, the data must be completely deleted from the system. In practice, this is embodied in algorithms of automatic and manual data deletion, and implementation of information destruction standards.
As an example, let’s use a simplified visualization of an imaginary online store data life cycle. Conventionally, the online store operates with three types of information: about products, about users, and statistics/marketing. In our case, there will be several sources of data collection, such as tracking user activity on the platform, web application data, databases of suppliers, integrated social network plugins, and data provided by users.
After collection, individual types of data are separated from the general flow. This is necessary due to the different requirements for different categories of data. For example, to fulfill an order, it is necessary to identify the product, compare its availability with the request, and process the buyer’s data including payment and personal identification information. Confidential data should be significantly more protected than corporate information like goods and their availability. Ideally, confidential information should not be collected at all, or at least all personal data must be deleted immediately after processing. However, in this way, the overall quality of service and customers’ user experience can degrade over a distance. Another compromise is complete automation of processes with data encryption and without the possibility of human intervention or access to information. In this way, users’ mistakes cannot be altered or deleted by marketplace support.
All information in the systems is stored somewhere, even if it is a matter of a few minutes. However, in the life cycle, the focus is mostly on long-term data storage. In the context of this example, appropriate storage would include encryption of users’ personal information, distribution of access rights to databases, pseudo-anonymization of users’ confidential information, safe protocols for internal and external information exchange, and backup protocols.
Disclosure of information and its transfer to a third party is gaining more and more popularity due to the variety of analytical and data processing services. However, the transfer of sensitive information outside the system is an additional risk factor that must be considered and controlled. This includes control over data transfer protocols, receiver jurisdiction, and third-party information security policies.
Destruction of data equals the end of the cycle. At the same time, the destruction can be completed only after removing information from all media, including backup copies, corporate and personal devices of the persons involved, cloud, and physical media. Under certain circumstances, partial deletion of data may be considered anonymization. For example, deleting data that allows you to distinguish and identify a specific user creates anonymized data, that can be used as statistics and reports.
Editing is not a separate stage of a life cycle, but it must be considered as a way to restart the cycle for edited information. Based on GDPR it is mandatory to provide the user access and the ability to edit their personal information. In addition to editing, the user must be able to completely delete their data and mentions from the system.
Learn more in this article: 5 Steps to GDPR Compliance
Risk control and negative events
Negative events are all events that pose a threat to information security. Risk control is aimed at reducing the probability of occurrence of negative events by determining the level of potential damage, probability of occurrence, and development of appropriate countermeasures.
Negative events can have many indications, but from the risk control point of view, only the probability of occurrence and the potential damage are important. For example, the risk factor is that most equipment tends to wear out or break. After making the appropriate calculations and tests, the manufacturers set the warranty period and the support period. Thus, using hardware that is no longer supported and has potentially reached its wear limit is highly likely to lead to negative events and risks. In comparison man-made disasters and climatic anomalies cannot be predicted, which makes them unforeseeable but still expected in most cases, like weather anomalies based on local climate or man-made disasters based on critical objects in the range (dams, chemical productions, etc.).
The level of potential harm from a negative event is correlated with countermeasures. Therefore, determining the upper threshold of damage is necessary for the development of high-quality algorithms and policies. For example, the loss of a corporate laptop can lead to unauthorized access to corporate and confidential files. In response to such a threat, it is necessary to develop countermeasures. Theft can be mitigated by restriction access to working areas of the office for outsiders. Loss of the device can be mitigated by the prohibition of moving the device out of the office. Unauthorized access to laptop data is mitigated by device media encryption, access rights distribution, and authorization policy.
Using similar logic, it is possible to create such a plan for each type of most common negative events.
| A negative event | Potential consequences | Solution |
| Theft of a corporate laptop | Disclosure of corporate information, unauthorized access to confidential data | Information encryption, access rights distribution, cloud-based data storage, data encryption. |
| Insider attack | Destruction/theft of corporate information | Limitation of access to information for different roles, automation of data processing. |
| Malfunction of the main server | Loss of key information | Data backup, media duplication, cloud-based backup. |
| Malware | Loss of key information, unauthorized access to information, disclosure of confidential data. | Algorithms for localization and damage control, backup of information, hardware and software tools for tracking malicious software, training in information security. |
| The leak of customers’ database | Disclosure of confidential information, sanctions from regulatory authorities. | Data encryption, database access control, data leak tracking. |
| Large-scale damage to the company infrastructure. (flood, fire, etc.) | Loss of corporate information, damage to equipment, loss of confidential data | Cloud storage of data, backup of information, remote storage of backup. |
| Unauthorized access to company premises | Tampering with equipment, leakage of corporate information, loss of equipment | Encryption of information carriers, restriction of physical access to equipment, tracking of access to key areas of the premises. |
The ultimate goal of the shown guidelines is not only the implementation of measures, aimed at reducing current risks but also for further development of the system. Alongside system development, new risk factors will appear. This means that previously developed countermeasures must continuously be adapted to internal and external factors.
Implementation of additional mechanisms in a system, increased load, or development of additional functions are internal factors. External factors are usually based on conditions, that are not connected to the system directly, like new technologies, new software (malware), and dedicated cyberattacks. As a result, algorithms must not only fulfill their core objective but also be flexible and cover most of the potential scenarios.
The technical aspect of GDPR compliance is a synthesis of methods, practical recommendations, hardware and software guidelines aimed at complying with requirements defined by the GDPR. Due to lots of aspects that are unique to each system, it is impossible to provide a single unified instruction for all cases. Thus, the actual solution is an individual approach based on continuous analysis and implementation of best management, cyber security, psychology and programming, and practices.